O que é, afinal, um data lake e por que ele importa para machine learning
A definição técnica de data lake é relativamente simples: trata-se de um repositório centralizado capaz de armazenar dados estruturados, semiestruturados e não estruturados em qualquer escala, sem a necessidade de um esquema predefinido. O dado entra no lago na sua forma bruta, tal como foi produzido pela fonte, e é transformado apenas quando necessário para um uso específico. Essa abordagem contrasta diretamente com a lógica dos data warehouses tradicionais, onde o dado precisa ser moldado em um esquema rígido antes mesmo de ser armazenado.
Para projetos de machine learning, essa flexibilidade não é um detalhe cosmético. É uma necessidade estrutural. Algoritmos de aprendizado de máquina se alimentam de volumes massivos de dados heterogêneos. Uma rede neural que aprende a identificar padrões de fraude precisa de logs de transações, dados cadastrais de clientes, históricos de comportamento, metadados de dispositivos e, eventualmente, dados de texto de interações com o serviço de atendimento. Formatos distintos, velocidades distintas de chegada, origens completamente diferentes.
Um data warehouse convencional teria dificuldade em absorver essa diversidade. O data lake, por sua natureza, acolhe tudo isso sem exigir que cada fonte seja normalizada antes da ingestão. Essa capacidade de processar e guardar dados em tempo real e em lote, combinando fontes de bancos de dados, dispositivos de Internet das Coisas, aplicativos móveis e outros sistemas, sem um esquema predefinido, é o que torna o data lake o substrato natural para iniciativas de inteligência artificial, conforme apontado em análise técnica publicada pela plataforma Encord em 2024.
Mas existe uma armadilha sedutora nessa liberdade. A ausência de estrutura na entrada não pode significar ausência de estrutura no todo. O paradoxo fundamental do data lake é que ele precisa ser livre o suficiente para absorver qualquer dado, mas organizado o suficiente para que qualquer cientista de dados consiga encontrar o que precisa, entender o que está vendo e confiar no que vai usar para treinar um modelo.
A anatomia de um data lake orientado a machine learning
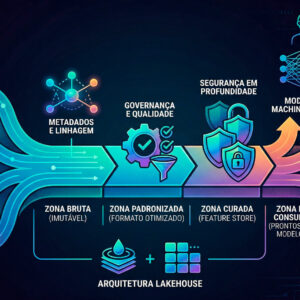
Compreender a estrutura interna de um data lake é o primeiro passo para construí-lo de forma útil. A arquitetura mais consolidada na literatura acadêmica e na prática industrial divide o data lake em camadas funcionais que representam diferentes estágios de maturidade do dado, desde sua chegada bruta até sua disponibilidade para consumo por modelos de aprendizado de máquina.
A camada de ingestão
Tudo começa na ingestão. Essa camada é responsável por capturar dados de fontes externas e internas e trazê-los para dentro do ecossistema do data lake. A ingestão pode ocorrer em modo de lote, onde grandes volumes são transferidos periodicamente, ou em modo de fluxo contínuo, onde os dados chegam em tempo real a partir de eventos, sensores ou transações.
Para projetos de machine learning, a decisão sobre o modo de ingestão tem consequências profundas. Modelos que precisam reagir a eventos em tempo real, como sistemas de recomendação ou detecção de anomalias, dependem de pipelines de streaming capazes de alimentar o lago com latência mínima. Modelos de treinamento periódico, como previsões mensais de demanda, podem se satisfazer com ingestão em lote.
O erro mais comum nessa camada é a falta de padronização do processo de chegada do dado. Quando cada equipe ou sistema alimenta o lago de um jeito diferente, sem metadados mínimos de identificação de origem, timestamp de geração ou versionamento, cria-se um problema de rastreabilidade que compromete toda a governança downstream. Desde o início, cada pipeline de ingestão deve ser capaz de registrar automaticamente informações essenciais sobre o dado que está sendo depositado no lago.
A zona bruta: onde a realidade chega sem filtro
O primeiro destino de qualquer dado que entra no lago é a zona bruta, chamada na literatura de raw zone ou landing zone. Aqui, os dados são armazenados exatamente como chegaram, sem transformação, sem limpeza, sem julgamento. Essa zona funciona como um arquivo histórico imutável da realidade tal como foi capturada.
A importância dessa imutabilidade para machine learning é frequentemente subestimada. Quando um modelo produz um resultado surpreendente ou incorreto, é necessário retornar à origem para entender o que aconteceu. Se os dados foram transformados antes do armazenamento e a versão original foi descartada, essa investigação se torna impossível. A zona bruta garante que sempre haverá uma versão fiel dos fatos originais disponível para auditoria e reprocessamento.
Do ponto de vista arquitetural, a zona bruta é tipicamente não exposta diretamente a usuários finais. Ela é acessível a engenheiros de dados e, em casos específicos, a cientistas de dados que precisam investigar anomalias nas fontes originais. Sua vida útil pode ser longa e seu custo de armazenamento deve ser otimizado com formatos comprimidos e políticas claras de retenção.
A zona padronizada: a primeira transformação
Entre a zona bruta e a zona curada existe, em muitas implementações modernas, uma zona intermediária de padronização. Seu papel é converter os dados para um formato unificado que facilite o processamento posterior, sem ainda aplicar regras de negócio ou limpeza semântica. Aqui, arquivos em formatos heterogêneos são convertidos para formatos otimizados para processamento analítico, como Parquet ou ORC, que permitem leitura colunar eficiente e integração direta com frameworks de machine learning.
Essa camada é especialmente relevante quando o data lake recebe dados de dezenas ou centenas de fontes distintas. Sem essa padronização, os processos de transformação seguintes precisariam lidar com a diversidade de formatos, o que aumenta a complexidade e reduz a performance. A padronização não é uma transformação semântica, não muda o significado dos dados, apenas reorganiza sua forma de armazenamento físico.
A zona curada: onde o dado ganha confiança
A zona curada, também chamada de conformed layer ou cleaned zone, é onde os dados passam por transformações substantivas: limpeza de valores ausentes, correção de inconsistências, normalização de unidades, deduplicação e integração de informações de fontes distintas. O dado que sai dessa zona tem uma característica fundamental que o diferencia de tudo que veio antes: pode ser confiado.
Para machine learning, a confiança no dado não é uma consideração filosófica. É uma questão técnica de primeira ordem. Modelos treinados em dados sujos, inconsistentes ou duplicados aprendem padrões equivocados e produzem previsões não confiáveis. O fenômeno é tão bem documentado que ganhou um nome próprio na literatura: garbage in, garbage out. A zona curada é a linha de defesa arquitetural contra esse problema.
Aqui também começam a ser definidas as features, as variáveis que os modelos de machine learning vão consumir. Feature stores, repositórios especializados para armazenar e servir variáveis de aprendizado de máquina de forma consistente e reproduzível, se integram naturalmente à zona curada. Essa integração garante que as mesmas features usadas no treinamento de um modelo sejam exatamente as mesmas servidas em produção, eliminando uma das principais fontes de divergência entre o ambiente de desenvolvimento e o ambiente de inferência.
A zona de consumo: o produto final
A zona de consumo é o ponto de chegada de todo o esforço de ingestão, padronização e curadoria. Aqui vivem os conjuntos de dados prontos para serem usados em treinamento de modelos, em dashboards analíticos, em aplicações de inteligência de negócio e em APIs que servem previsões em tempo real. Essa zona é altamente estruturada, fortemente documentada e submetida a controles rigorosos de acesso.
Uma arquitetura que tem se consolidado como padrão para a zona de consumo em projetos de machine learning é a chamada Medallion Architecture, que classifica os dados em camadas denominadas bronze, prata e ouro, onde o bronze corresponde aos dados brutos e o ouro corresponde aos dados curados e prontos para consumo analítico e por modelos de IA, conforme descrito em análise publicada pela plataforma LakeFS em 2025.
A zona exploratória: o laboratório dos cientistas de dados
Existe uma zona que muitas arquiteturas esquecem de incluir e cuja ausência cobra um preço alto no cotidiano das equipes de data science: a zona exploratória, também chamada de sandbox. Trata-se de um espaço seguro e isolado onde cientistas de dados podem experimentar com dados, testar hipóteses, desenvolver novas features e prototipar modelos sem o risco de contaminar o ambiente de produção.
A importância dessa zona foi destacada em análise técnica da Capital One, que identificou que a zona exploratória habilita casos de uso de machine learning e funciona como uma área de experimentação cujas exigências de governança, completude e ciclo de vida diferem das outras zonas. Essa diferença não é uma concessão à desordem. É o reconhecimento de que inovação requer um espaço protegido para o erro controlado.
Metadados: o sistema nervoso do data lake
Se as zonas são o esqueleto do data lake, os metadados são seu sistema nervoso. Sem uma gestão robusta de metadados, o lago mais bem organizado do mundo se transforma em um labirinto opaco, onde ninguém sabe o que existe, quem criou, quando foi atualizado ou como pode ser usado.
A literatura acadêmica distingue três categorias fundamentais de metadados que precisam ser gerenciadas em um data lake orientado a machine learning. Os metadados técnicos descrevem a estrutura física dos dados: esquema, tipos de dados, formato de armazenamento, particionamento, tamanho. Os metadados de negócio descrevem o significado semântico: o que cada campo representa, de qual sistema veio, qual unidade de medida usa, quem é o responsável. E os metadados operacionais descrevem o comportamento dinâmico: quando o dado foi atualizado, quantas vezes foi acessado, quais pipelines o processaram, qual linhagem de transformações ele sofreu.
Para machine learning, a linhagem dos dados, o rastreamento de toda a cadeia de transformações que um dado sofreu desde sua origem até sua forma atual, não é apenas uma boa prática de governança. É um requisito de reprodutibilidade científica. Um modelo de machine learning deve poder ser replicado com exatidão, o que exige que todos os dados usados em seu treinamento possam ser identificados e recuperados na mesma forma em que foram consumidos. Sem linhagem de dados, a reprodutibilidade de modelos é uma ilusão.
Ferramentas de catálogo de dados, como Apache Atlas e AWS Glue Data Catalog, são a implementação prática desse sistema de metadados. Elas permitem que engenheiros e cientistas de dados descubram quais dados existem no lago, entendam sua procedência e avaliem sua qualidade antes de usá-los em qualquer análise ou treinamento de modelo.
Governança de dados: a disciplina que transforma lago em ativo
Nenhuma discussão sobre data lake para machine learning está completa sem uma análise honesta do papel da governança. Governança de dados é o conjunto de políticas, processos, papéis e tecnologias que garantem que os dados de uma organização sejam precisos, consistentes, seguros, rastreáveis e usados de forma apropriada.
Em 2024, pesquisa conduzida pela empresa Precisely identificou que a qualidade dos dados é a prioridade máxima de integridade de dados, citada por 60% dos respondentes, evidenciando a importância crítica de implementar monitoramento automatizado de qualidade que avalie continuamente precisão, completude e consistência em todos os tipos de dados, conforme analisado em guia arquitetural publicado pela Alation em 2025.
Para projetos de machine learning, a governança apresenta desafios específicos que vão além dos controles tradicionais de acesso e qualidade. A questão da privacidade dos dados de treinamento tornou-se especialmente sensível com a proliferação de regulamentos como o RGPD na Europa e a LGPD no Brasil. Modelos de machine learning podem, inadvertidamente, memorizar informações pessoais dos dados com que foram treinados, criando riscos de exposição que precisam ser endereçados na arquitetura do lago antes que os dados cheguem aos cientistas de dados.
Técnicas como anonimização, pseudonimização e computação diferencial privada precisam ser incorporadas aos pipelines de processamento do data lake, não adicionadas como uma camada de correção posterior. A governança que funciona é a que está embutida na arquitetura desde o primeiro dia.
Outro aspecto crítico da governança em contextos de machine learning é o controle de versão dos dados. Modelos de aprendizado de máquina são profundamente sensíveis às características dos dados com que foram treinados. Quando os dados de entrada mudam, seja por uma correção em um pipeline upstream, seja por uma mudança na definição de um campo, seja por uma nova fonte de dados, o modelo pode passar a produzir resultados diferentes sem que ninguém tenha tocado no código. Esse fenômeno, conhecido como data drift, é uma das principais causas de degradação silenciosa de modelos em produção.
A solução arquitetural é o versionamento dos conjuntos de dados: cada conjunto de dados usado para treinar um modelo deve ser identificado de forma única e imutável, de modo que seja sempre possível saber exatamente com quais dados um modelo foi treinado e reproduzir esse treinamento identicamente no futuro.
A ascensão do data lakehouse: convergência entre flexibilidade e confiabilidade
A fronteira entre data lake e data warehouse tem se dissolvido nos últimos anos, dando origem a uma arquitetura híbrida que capturou a atenção da comunidade acadêmica e da indústria: o data lakehouse. Essa arquitetura combina a flexibilidade e o custo-benefício do data lake com as capacidades de gerenciamento e governança do data warehouse, criando um sistema que consegue ingerir e armazenar dados não estruturados em alta velocidade ao mesmo tempo em que suporta consultas analíticas sofisticadas com desempenho e confiabilidade.
O artigo fundacional da arquitetura lakehouse, coescrito por pesquisadores da Databricks, Berkeley e Stanford, demonstrou que tecnologias de código aberto podem rivalizar com data warehouses proprietários em desempenho, ao mesmo tempo em que oferecem a abertura e a flexibilidade necessárias para cargas de trabalho de machine learning modernas. Em 2024, pesquisas adicionais publicadas por grupos ligados a essa plataforma introduziram conceitos como Delta Tensor, um sistema projetado para armazenar embeddings de machine learning de forma eficiente usando formatos de armazenamento otimizados para esse ecossistema.
A publicação da ScienceDirect de 2024, em estudo experimental e survey abrangente, confirmou que a arquitetura lakehouse representa uma solução superior para a gestão eficiente de big data, combinando a força de data warehouses e data lakes para processar e mesclar dados rapidamente enquanto ingere e armazena dados não estruturados de alta velocidade com capacidades de transformação e análise pós-armazenamento.
Para machine learning, o lakehouse oferece uma vantagem específica que vai além da performance: ele suporta transações com garantias ACID, o acrônimo para atomicidade, consistência, isolamento e durabilidade, que são as propriedades que garantem a integridade dos dados em operações concorrentes. Sem essas garantias, pipelines de machine learning que leem e escrevem dados simultaneamente, algo comum em cenários de aprendizado online ou de atualização contínua de features, correm o risco de consumir estados inconsistentes dos dados.
Integração com o ciclo de vida de machine learning
Um data lake para machine learning não vive isolado. Ele se integra a um ecossistema mais amplo de ferramentas e processos que compõem o que a indústria chama de MLOps, o conjunto de práticas que transporta os modelos de machine learning do laboratório para a produção e os mantém funcionando com qualidade ao longo do tempo.
Essa integração começa na fase de exploração, quando os cientistas de dados precisam descobrir quais dados estão disponíveis, qual é a qualidade desses dados e como eles se relacionam entre si. Um catálogo de dados rico, com metadados bem mantidos e interfaces de busca eficientes, reduz dramaticamente o tempo que essa fase consome. Em muitas organizações, a exploração de dados consome entre 50% e 80% do tempo total de um projeto de machine learning. Uma arquitetura de data lake bem planejada pode reduzir esse número pela metade.
Na fase de preparação de dados, os pipelines do data lake se tornam os pipelines de feature engineering. As transformações que preparam os dados para treinamento de modelos devem ser versionadas, testadas e executadas de forma reproduzível, com os resultados armazenados em feature stores que garantem consistência entre treinamento e inferência. A integração entre o data lake e o feature store é um dos pontos de maior impacto na qualidade e na manutenibilidade de sistemas de machine learning em produção.
Na fase de treinamento, os modelos consomem dados diretamente das camadas curadas do data lake, idealmente através de interfaces que abstraem a complexidade do armazenamento subjacente e garantem que o acesso seja eficiente mesmo para conjuntos de dados na escala de petabytes. Plataformas como Amazon SageMaker, Azure Machine Learning e Databricks MLflow se integram nativamente com os principais sistemas de armazenamento de data lakes, precisamente porque esse padrão de integração se tornou parte da arquitetura padrão de machine learning em escala.
Na fase de monitoramento, após o modelo estar em produção, o data lake assume um papel que poucos arquitetos consideram desde o início: o armazenamento dos dados de inferência e dos resultados gerados pelo modelo ao longo do tempo. Esses dados são essenciais para detectar degradação de performance, identificar data drift e coletar exemplos para retreinamento. Um data lake que não foi projetado para absorver esse fluxo de dados de produção criará gargalos que vão impedir o monitoramento eficaz dos modelos.
Escalabilidade e performance: construindo para o futuro
Um data lake que funciona bem com cem gigabytes de dados pode se tornar um pesadelo operacional quando cresce para cem terabytes. E um que funciona bem com cem terabytes pode se tornar inutilizável na escala de petabytes. A escalabilidade não é uma característica que se adiciona depois. É uma propriedade que precisa ser incorporada nas decisões arquiteturais desde o início.
O mercado global de data lake foi estimado em 13,62 bilhões de dólares em 2023 e está projetado para crescer a uma taxa composta de 23,6% ao ano até 2030, segundo dados da Grand View Research citados em análise da Alation em 2025. Esse crescimento reflete não apenas a adoção crescente da tecnologia, mas também o aumento contínuo dos volumes de dados que precisam ser gerenciados.
As plataformas de armazenamento em nuvem, como Amazon S3, Azure Data Lake Storage e Google Cloud Storage, oferecem escalabilidade praticamente ilimitada em termos de capacidade de armazenamento. O desafio real da escalabilidade em data lakes modernos não é quanto dados podem ser armazenados, mas com que eficiência esses dados podem ser acessados e processados conforme o volume cresce.
Particionamento inteligente dos dados, estratégias de compactação de arquivos, uso de formatos colunar otimizados e políticas de ciclo de vida que movem dados menos acessados para camadas de armazenamento mais baratas são as principais alavancas de performance e custo em data lakes de grande escala. Para machine learning, o particionamento merece atenção especial: quando os dados são particionados de acordo com as dimensões mais frequentemente usadas para filtrar conjuntos de treinamento, como data, região geográfica ou categoria de produto, o tempo de preparação dos conjuntos de treinamento pode ser reduzido em ordens de magnitude.
Segurança em profundidade: protegendo o ativo mais valioso
Um data lake de machine learning concentra, por definição, os dados mais valiosos de uma organização. Dados de clientes, registros de transações, propriedade intelectual incorporada em features e modelos, todos convergem para esse repositório central. Isso o torna um alvo de alto valor e exige uma abordagem de segurança que vai muito além de um simples controle de acesso por senha.
A arquitetura de segurança de um data lake moderno opera em múltiplas camadas. Na camada de rede, o acesso ao lago é restrito a redes privadas virtuais e controlado por firewalls que limitam quais sistemas podem se comunicar com quais componentes. Na camada de identidade, cada usuário, serviço ou pipeline que acessa o lago precisa se autenticar com credenciais únicas e seus acessos são registrados em logs de auditoria imutáveis. Na camada de dados, a criptografia em repouso protege os arquivos armazenados e a criptografia em trânsito protege os dados enquanto se movem entre componentes.
Para machine learning, existe uma camada adicional de segurança que raramente é discutida em textos introdutórios: a proteção dos modelos contra ataques adversariais baseados em dados. Quando atores maliciosos conseguem inserir dados corrompidos no pipeline de treinamento, eles podem influenciar o comportamento do modelo de maneiras sutis e difíceis de detectar. Esse tipo de ataque, conhecido como data poisoning, é uma ameaça real em sistemas que ingerem dados de fontes externas não completamente confiáveis. A arquitetura do data lake deve incluir mecanismos de validação e isolamento que previnam que dados de origem duvidosa cheguem diretamente aos pipelines de treinamento.
Do data lake ao data lake de inteligência artificial generativa
A ascensão dos grandes modelos de linguagem e das aplicações de inteligência artificial generativa está reconfigurando os requisitos para a arquitetura de data lakes. Esse é um ponto de inflexão que merece atenção de qualquer arquiteto de dados que queira construir infraestrutura com longevidade.
A análise publicada na MLOps Community em 2025 identifica com precisão o problema central: a arquitetura de data lake, com todos os seus benefícios para garantir qualidade de dados para analytics, é inerentemente lenta. A jornada do dado bruto até um estado limpo e utilizável envolve etapas de ingestão, validação e transformação que podem levar horas ou mesmo dias. Uma aplicação de geração aumentada por recuperação, o modelo de arquitetura dominante em IA generativa empresarial, não pode esperar por esse processamento. A informação chegaria obsoleta.
Isso não significa que o data lake se tornou obsoleto. Significa que ele precisa coexistir com abordagens complementares que atendam aos casos de uso de IA generativa com os requisitos de latência que esses sistemas exigem. Bancos de dados vetoriais, que armazenam representações matemáticas do significado semântico de textos e imagens e permitem busca por similaridade em milissegundos, estão se tornando componentes essenciais do ecossistema de dados ao lado dos data lakes tradicionais.
A Databricks introduziu em 2023 um componente de busca vetorial em sua plataforma lakehouse que converte dados e consultas em vetores em um espaço multidimensional chamado de embeddings, derivado de modelos de inteligência artificial generativa, permitindo que resultados semanticamente similares sejam encontrados com alta velocidade. Essa convergência entre o data lake e a infraestrutura de IA generativa representa a próxima fronteira da arquitetura de dados empresariais.
Armadilhas comuns e como evitá-las
Nenhum artigo sobre data lake para machine learning seria honesto sem uma discussão franca sobre as armadilhas que derrubam os projetos mais bem-intencionados. A experiência acumulada na literatura acadêmica e na prática industrial aponta para um conjunto recorrente de erros que se repetem em organizações de todos os tamanhos e setores.
A primeira armadilha é a confusão entre ingestão e governança. Muitas organizações constroem pipelines de ingestão sofisticados que absorvem dados de dezenas de fontes, mas negligenciam a camada de metadados e governança. O resultado é um lago cheio de dados que ninguém consegue usar, porque ninguém sabe o que existe, onde encontrar, quem é responsável ou se pode ser confiado. Dados sem metadados são como livros sem títulos em uma biblioteca sem catálogo: existem, mas são inacessíveis.
A segunda armadilha é a ausência de uma zona exploratória estruturada. Quando os cientistas de dados não têm um ambiente seguro para experimentação, eles naturalmente passam a trabalhar diretamente sobre as zonas de produção do lago, corrompendo dados, criando arquivos temporários que nunca são removidos e introduzindo dependências não documentadas entre experimentos e dados de produção.
A terceira armadilha é a falta de controle de qualidade automatizado. Qualidade de dados não é uma propriedade que existe naturalmente. É um resultado de processos ativos de monitoramento, validação e correção. Um data lake sem um sistema robusto de verificação de qualidade vai, inevitavelmente, se degradar ao longo do tempo à medida que novas fontes são adicionadas, pipelines são modificados e o volume de dados cresce além da capacidade de inspeção manual.
A quarta armadilha é o esquecimento do custo. Data lakes em nuvem podem se tornar surpreendentemente caros quando crescem sem uma política clara de ciclo de vida dos dados. Dados que foram ingeridos há anos, nunca acessados e armazenados em camadas de alta performance representam dinheiro desperdiçado. Políticas de retenção, arquivamento e exclusão de dados precisam ser definidas desde o início e aplicadas automaticamente.
A quinta armadilha, talvez a mais cara de todas, é a falta de alinhamento entre a arquitetura técnica e os casos de uso de negócio. Um data lake construído sem uma compreensão clara de quais perguntas precisa responder, quais modelos precisa alimentar e quais decisões precisa suportar vai ser uma solução à procura de um problema. A arquitetura deve sempre partir dos requisitos concretos dos projetos de machine learning e das iniciativas de analytics que precisa habilitar.
Um roteiro pragmático para começar
Para as organizações que estão iniciando a jornada de construção de um data lake para machine learning, a proliferação de escolhas tecnológicas pode ser paralisante. Amazon S3, Azure Data Lake Storage, Google Cloud Storage, Apache Hadoop, Delta Lake, Apache Iceberg, Apache Hudi: cada uma dessas tecnologias tem um conjunto de defensores apaixonados e casos de uso onde brilha.
Mas a verdade inconveniente é que a escolha da tecnologia importa muito menos do que a clareza dos princípios arquiteturais. Um data lake bem projetado em qualquer uma dessas plataformas vai superar um data lake mal projetado em qualquer outra. Os princípios que fazem a diferença são os que atravessam todo este artigo: separação clara de zonas, gestão rigorosa de metadados, governança incorporada desde o início, integração com o ciclo de vida completo de machine learning e escalabilidade planejada desde o início.
O ponto de partida recomendado não é a escolha da tecnologia. É a identificação dos três ou quatro casos de uso de machine learning mais importantes para a organização nos próximos dezoito meses. A arquitetura deve ser desenhada para servir a esses casos de uso com excelência, e depois expandida incrementalmente para servir a casos de uso adicionais. Um data lake que tenta ser tudo para todo mundo desde o primeiro dia raramente se torna excelente em coisa alguma.
O lago que alimenta o futuro
No começo deste artigo, descrevemos o paradoxo das organizações modernas: dados abundantes, conhecimento escasso. O data lake bem estruturado é a resposta arquitetural a esse paradoxo. Mas é uma resposta que exige comprometimento com princípios que vão além da tecnologia: disciplina na organização das zonas de dados, rigor na gestão de metadados, seriedade na governança, atenção à segurança e alinhamento constante com os casos de uso que justificam toda essa infraestrutura.
O machine learning, em sua essência, é a arte de aprender com dados. Um data lake bem construído é o ambiente onde esse aprendizado pode acontecer em escala, com qualidade, com reprodutibilidade e com a confiança de que os dados que alimentam os modelos refletem a realidade com a maior fidelidade possível.
As organizações que dominarem essa arquitetura não estarão apenas construindo repositórios de dados. Estarão construindo a infraestrutura fundamental da inteligência organizacional do século vinte e um. Estarão construindo o lago que alimenta o futuro.
Fontes
- Giebler, C., et al. (2021). Toward data lakes as central building blocks for data management and analysis. PMC / Frontiers in Big Data.
https://pmc.ncbi.nlm.nih.gov/articles/PMC9442782/ - Sawadogo, P., & Darmont, J. (2021). On data lake architectures and metadata management. Journal of Intelligent Information Systems, 56(1), 97–120.
https://link.springer.com/article/10.1007/s10844-020-00608-7 - Azeroual, O., et al. (2024). Data Lakes: A Survey of Concepts and Architectures. Computers, 13(7), 183. MDPI.
https://www.mdpi.com/2073-431X/13/7/183 - Fard, A., et al. (2024). Data Lakehouse: A survey and experimental study. ScienceDirect / Information Systems.
https://www.sciencedirect.com/science/article/pii/S0306437924001182 - Armbrust, M., et al. (2021). Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics. CIDR 2021.
https://www.cidrdb.org/cidr2021/papers/cidr2021_paper17.pdf - Srinivas, K., et al. (2023). LakeBench: Benchmarks for data discovery over data lakes. arXiv:2307.04217.
https://arxiv.org/abs/2307.04217 - LakeMLB: Data Lake Machine Learning Benchmark. arXiv, February 2026.
https://arxiv.org/html/2602.10441 - Worlikar, S., Patel, H., & Challa, A. (2025). Integrating Lakehouse Architectures and Cloud Data Warehousing for Next-Generation Enterprise Analytics. International Journal of Modern Computer Science and IT Innovations.
https://aimjournals.com/index.php/ijmcsit/article/view/464 - NVIDIA Developer Blog. (2023). Evaluating Data Lakes and Data Warehouses as Machine Learning Data Repositories.
https://developer.nvidia.com/blog/evaluating-data-lakes-and-data-warehouses-as-machine-learning-data-repositories/ - LakeFS Blog. (2025). Building a Data Lake for the GenAI and ML Era.
https://lakefs.io/blog/building-data-lake-genai-ml-era/ - Encord Blog. (2024). Data Lake Explained: A Comprehensive Guide for ML Teams.
https://encord.com/blog/data-lake-guide/ - AWS Documentation. Logical architecture of modern data lake centric analytics platforms. AWS Serverless Data Analytics Pipeline Whitepaper.
https://docs.aws.amazon.com/whitepapers/latest/aws-serverless-data-analytics-pipeline/logical-architecture-of-modern-data-lake-centric-analytics-platforms.html - Capital One Tech Blog. Data Lake Architecture: What is a Zone?
https://www.capitalone.com/tech/cloud/data-lake-zones/ - Alation Blog. (2025). Data Lake Architecture: Complete Guide to Modern Data Management.
https://www.alation.com/blog/data-lake-architecture-guide/ - MLOps Community. (2025). The Great Data Divergence: Why Generative AI Demands a New Approach Beyond the Data Lake.
https://mlops.community/the-great-data-divergence-why-generative-ai-demands-a-new-approach-beyond-the-data-lake/ - DataCamp Tutorial. (2024). A Comprehensive Guide to Databricks Lakehouse AI For Data Scientists.
https://www.datacamp.com/tutorial/comprehensive-guide-to-databricks-lakehouse-ai