O dia em que o monólito desmoronou
Era uma sexta-feira à tarde quando os engenheiros da Netflix perceberam que tinham um problema que não conseguiam mais ignorar. O sistema de recomendações aquele que sugere o próximo episódio que você vai maratonar havia crescido tanto, tornado-se tão intrincado dentro da grande arquitetura monolítica da empresa, que qualquer mudança nele exigia semanas de testes e colocava em risco o funcionamento de serviços completamente diferentes, como o sistema de pagamentos ou o catálogo de filmes. Não era uma falha de engenharia. Era uma falha arquitetural, e ela representava o estado de praticamente toda a indústria de software até meados dos anos 2010.
Hoje, em 2026, o cenário é radicalmente diferente. A Netflix opera com centenas de microsserviços independentes. O sistema que recomenda conteúdo não sabe e não precisa saber como funciona o sistema que processa seu pagamento mensal. Cada serviço vive em seu próprio universo, escala de forma autônoma, falha sem derrubar os vizinhos e evolui sem pedir permissão ao resto da plataforma. E dentro desse ecossistema fragmentado, inteligência artificial encontrou seu habitat natural.
Este artigo é sobre essa convergência o encontro entre a arquitetura de microsserviços e os sistemas de inteligência artificial escaláveis. Uma convergência que não é apenas técnica, mas estratégica, organizacional e, em muitos sentidos, filosófica. Uma convergência que está redefinindo o que significa construir software no século XXI.
O que são microsserviços e por que a IA precisava deles
Da catedral à feira livre
Para entender por que microsserviços e IA formam uma parceria tão poderosa, é preciso primeiro entender o problema que cada um resolve e por que esses problemas são, no fundo, o mesmo problema visto de ângulos diferentes.
A arquitetura monolítica tradicional funciona como uma catedral: um edifício grandioso, projetado de uma vez só, onde cada pedra está em contato direto com as outras. Remover ou modificar uma coluna pode colocar em risco a estrutura inteira. O sistema de banco de dados conversava diretamente com a camada de negócios, que por sua vez estava costurada à camada de apresentação. Tudo compartilhava o mesmo processo, o mesmo espaço de memória, o mesmo ciclo de deploy.
A arquitetura de microsserviços propõe o oposto: uma feira livre. Cada barraca é independente, tem seu próprio dono, seu próprio estoque, suas próprias regras. Se uma barraca fecha cedo, as outras continuam funcionando. Se uma barraca precisa de mais espaço para guardar mercadorias, ela se expande sem consultar as vizinhas. A comunicação acontece através de interfaces bem definidas os contratos de API em vez de dependências diretas no código.
A definição acadêmica é precisa: uma arquitetura de microsserviços decompõe aplicações em serviços menores, independentemente implantáveis, que se comunicam através de interfaces bem definidas. Cada serviço é alinhado a uma capacidade de negócio específica e pode ser desenvolvido, implantado e escalado de forma autônoma. Segundo um estudo sistemático publicado na revista Computing pelo Springer Nature em março de 2025, que analisou 269 trabalhos acadêmicos sobre o tema, o uso de IA em microsserviços emergiu como um campo significativo e em rápido crescimento, com publicações aumentando substancialmente a partir de 2019.
Por que a IA precisava exatamente disso
Um sistema de inteligência artificial de produção não é simplesmente um modelo de machine learning. É uma orquestra. Tem um serviço responsável pela ingestão e limpeza de dados, outro que treina e versiona os modelos, outro que serve as previsões em tempo real, outro que monitora o desempenho do modelo em produção, outro que detecta quando o modelo começa a degradar o chamado data drift e dispara um novo ciclo de treinamento. Tente encaixar tudo isso em uma aplicação monolítica e você terá um pesadelo de acoplamento: mudar o algoritmo de pré-processamento pode quebrar o serviço de inferência; escalar a capacidade de treinamento vai escalar também, desnecessariamente, o módulo de monitoramento.
A arquitetura de microsserviços resolve isso de forma elegante. Cada componente do pipeline de IA se torna um serviço independente. O serviço de feature engineering pode ser atualizado sem tocar no serviço de inferência. O serviço de treinamento pode ser escalado massivamente durante uma rodada de retreinamento e depois reduzido a zero quando o trabalho termina, sem impactar a latência das previsões em produção.
Conforme documentado em um artigo publicado no International Journal of Computer Engineering and Technology em 2024, microsserviços permitem a escalabilidade independente de componentes de aplicações, permitindo que cargas de trabalho de IA cresçam eficientemente à medida que a demanda aumenta e essa modularidade ajuda equipes a implantar, atualizar e otimizar recursos de IA sem impactar o sistema inteiro.
A anatomia de um sistema de IA baseado em microsserviços
As camadas do ecossistema
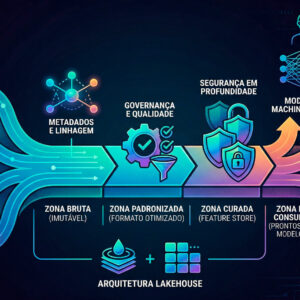
Quando se projeta um sistema de IA sobre uma fundação de microsserviços, emerge uma estrutura em camadas que é tanto lógica quanto elegante. Compreender cada camada é essencial para entender como o todo funciona e por que ele escala.
A camada mais fundamental é a de ingestão e processamento de dados. Aqui vivem os serviços responsáveis por capturar dados de fontes diversas bases de dados relacionais, streams de eventos, APIs externas, dispositivos IoT e transformá-los em um formato que os modelos de machine learning possam consumir. Esta camada frequentemente utiliza plataformas de streaming como Apache Kafka, que permite processar e transmitir volumes massivos de dados em tempo real entre serviços sem criar acoplamento direto.
Acima dela está a camada de feature store o repositório centralizado de características calculadas. Este serviço resolve um dos problemas mais insidiosos dos sistemas de IA: a duplicação de lógica de feature engineering entre o ambiente de treinamento e o ambiente de produção. Quando treinamento e inferência calculam as mesmas características de formas ligeiramente diferentes, o modelo aprende em um mundo e opera em outro. O feature store centralizado elimina essa assimetria.
A camada de treinamento contém os serviços que constroem, otimizam e versionam os modelos. Em um sistema bem projetado, este serviço é acionado automaticamente por eventos um volume suficiente de novos dados, uma degradação detectada na performance do modelo em produção, uma mudança nos padrões de dados. Ferramentas como Kubeflow Pipelines, que internamente utiliza Argo Workflows, e o MLflow para registro de experimentos e versões de modelos, habitam esta camada.
A camada de inferência ou model serving é onde o sistema entrega valor ao usuário final. Aqui, os modelos treinados são expostos como APIs que respondem a perguntas em tempo real. Frameworks especializados como KServe, Seldon Core e BentoML tornaram-se os padrões de mercado para esta camada, cada um com tradeoffs distintos entre flexibilidade, performance e facilidade de operação.
Finalmente, a camada de observabilidade permeia todas as outras. Ferramentas como Prometheus para coleta de métricas, Grafana para visualização e Jaeger para rastreamento distribuído garantem que os engenheiros possam entender o comportamento do sistema, identificar gargalos e responder a incidentes antes que eles afetem os usuários.
O padrão de decomposição: Como definir fronteiras de serviço
A questão mais difícil em qualquer projeto de microsserviços não é tecnológica é arquitetural: como dividir o sistema? Onde traçar as fronteiras entre serviços? Para sistemas de IA, esta questão tem dimensões adicionais de complexidade.
A abordagem mais robusta é o Domain-Driven Design (DDD), popularizado por Eric Evans. O DDD propõe que as fronteiras de serviço devam espelhar as fronteiras do domínio de negócio os chamados bounded contexts. Em um sistema de IA para recomendações de e-commerce, por exemplo, o domínio de “comportamento do usuário” é naturalmente separado do domínio de “características do produto”, que por sua vez é distinto do domínio de “geração de recomendações”.
Uma revisão sistemática da literatura publicada na revista MDPI em março de 2025, analisando 43 estudos publicados entre 2018 e 2024, revelou que técnicas de machine learning incluindo algoritmos de clustering como k-Means e Word Embeddings são crescentemente utilizadas para automatizar e aprimorar o próprio processo de decomposição de microsserviços. Em outras palavras, a IA está sendo usada para projetar melhores arquiteturas de sistemas que rodarão mais IA. O processamento de linguagem natural foi aplicado em 32,6% dos estudos analisados, principalmente para analisar requisitos textuais e auxiliar na identificação de microsserviços.
O artigo publicado no International Journal of Recent Engineering Science em 2025, intitulado “The Evolution and Future of Microservices Architecture with AI-Driven Enhancements”, aponta que agentes autônomos de IA são crescentemente capazes de interagir e gerenciar microsserviços, reduzindo a intervenção humana e aumentando a eficiência do sistema e a chave está exatamente em como se definem as fronteiras desses serviços desde o início.
A infraestrutura kubernetes, contêineres e o service mesh
Ascensão do kubernetes como lingua franca
Se os microsserviços são os cidadãos deste novo mundo, o Kubernetes é o governo que os administra. Originalmente desenvolvido pelo Google e aberto à comunidade em 2014, o Kubernetes tornou-se o padrão absoluto para orquestração de contêineres e, consequentemente, para a operação de sistemas de IA em escala.
O que torna o Kubernetes tão essencial para sistemas de IA? Antes de tudo, sua capacidade de escalonamento automático. O Horizontal Pod Autoscaler monitora métricas como utilização de CPU e memória e ajusta automaticamente o número de instâncias de um serviço para corresponder à demanda. Para um serviço de inferência de modelos de machine learning, isto significa que a carga de trabalho escala automaticamente durante períodos de pico a hora do almoço em um sistema de delivery, por exemplo e reduz quando a demanda cai, otimizando custos.
Pesquisas publicadas no portal Cloud Native Now em 2025 destacam que ferramentas como Kubeflow, TensorFlow Serving e Seldon Core facilitam significativamente a implantação de modelos de ML como microsserviços, com o Kubernetes gerenciando alta disponibilidade e balanceamento de carga, garantindo inferência com baixa latência. Um estudo de caso publicado no International Journal of Science and Computer Applications em 2025 validou uma arquitetura cloud-native em produção na AWS, demonstrando latência de inferência no percentil 95 abaixo de 120 milissegundos com 100 requisições por segundo — resultados que seriam impossíveis sem a orquestração automática do Kubernetes.
A containerização o ato de empacotar um modelo de machine learning junto com todas as suas dependências em uma unidade portátil e reproduzível é o que torna possível o “funciona na minha máquina” deixar de ser uma piada e passar a ser uma garantia operacional. Cada microsserviço de IA, com seu modelo, suas dependências de Python, suas variáveis de ambiente, vive dentro de um contêiner que se comporta da mesma forma em qualquer ambiente, do laptop do desenvolvedor ao cluster de produção com centenas de máquinas.
O service mesh: A camada invisível que mantém tudo funcionando
À medida que um sistema de microsserviços cresce de dezenas para centenas de serviços emerge um problema que é tanto técnico quanto humano: como garantir que a comunicação entre todos esses serviços seja segura, confiável, observável e performante? Como implementar timeouts, circuit breakers, retentativas automáticas e criptografia de tráfego em cada um dos serviços sem duplicar esse código repetidamente?
A resposta da indústria é o service mesh: uma camada de infraestrutura dedicada que abstrai as complexidades da comunicação entre serviços. Ferramentas como Istio e Linkerd injetam um proxy sidecar um contêiner auxiliar ao lado de cada microsserviço. Este proxy intercepta todo o tráfego de entrada e saída do serviço e aplica políticas de segurança, coleta métricas e implementa padrões de resiliência, sem que o código da aplicação precise saber que isso está acontecendo.
Para sistemas de IA, o service mesh tem implicações profundas. O padrão de circuit breaker, por exemplo, evita que a falha de um serviço de modelo se propague em cascata pelo sistema inteiro. Se o serviço de recomendações começa a responder lentamente talvez porque o modelo subjacente está sendo atualizado o circuit breaker abre e o sistema automaticamente cai back para uma estratégia de recomendação simplificada, em vez de deixar toda a plataforma emperrar aguardando uma resposta que nunca virá.
Conforme documentado em um estudo publicado pelo International Research Journal on Advanced Engineering Hub em 2025, que examinou implantações de microsserviços em empresas como Netflix, Amazon e Uber, a implementação de padrões de circuit breaker resultou em 58% de redução de erros, e orquestração avançada gerou 30% de economia de energia. Números que falam por si.
Infraestrutura como código: O princípio da reprodutibilidade
Um dos axiomas do MLOps moderno é que toda a infraestrutura deve ser definida em código o que a comunidade chama de Infrastructure as Code (IaC). Ferramentas como Terraform, Helm e Kubernetes Operators permitem que equipes definam exatamente como seus serviços de IA devem ser implantados: quantas réplicas, quanta memória, quais políticas de escalonamento, quais regras de rede.
A importância disso para sistemas de IA vai além da conveniência operacional. Experimentos de machine learning são notoriamente difíceis de reproduzir. Quando o ambiente de infraestrutura também pode mudar entre corridas de treinamento, o problema se multiplica. IaC garante que o ambiente de treinamento de hoje seja idêntico ao de amanhã, e que o ambiente de produção seja idêntico ao de staging eliminando uma categoria inteira de bugs que de outra forma seriam quase impossíveis de diagnosticar.
MLOps: A disciplina que conecta ciência e operações
O que é MLOps e por que ele existe
Há uma crise silenciosa no mundo da inteligência artificial empresarial: a maioria dos modelos de machine learning que são desenvolvidos nunca chega à produção. E dos que chegam, muitos degradam silenciosamente ao longo do tempo, respondendo às perguntas de hoje com os padrões de ontem. Esta crise tem um nome: a lacuna entre ciência de dados e operações de software.
O MLOps Machine Learning Operations nasceu para fechar essa lacuna. Trata-se da aplicação dos princípios do DevOps ao ciclo de vida de modelos de machine learning: automação, integração contínua, entrega contínua, monitoramento e feedback loops. A Microsoft, em sua documentação oficial para o Azure Kubernetes Service, define MLOps como “práticas que facilitam a colaboração entre cientistas de dados, operações de TI e stakeholders de negócio, garantindo que modelos de machine learning sejam desenvolvidos, implantados e mantidos de forma eficiente.”
O ciclo de vida completo inclui: treinamento, empacotamento, validação, implantação, monitoramento e retreinamento. Em um sistema baseado em microsserviços, cada etapa desse ciclo pode ser implementada como um serviço independente, orquestrada por ferramentas como Argo Workflows ou Kubeflow Pipelines, e monitorada através de stacks de observabilidade baseadas em Prometheus e Grafana.
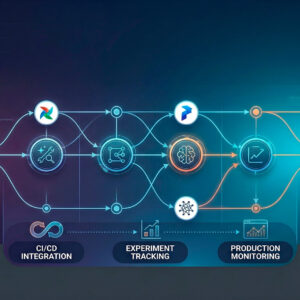
O pipeline de CI/CD para modelos de IA
Um dos avanços mais significativos da última meia década é a extensão dos pipelines de integração e entrega contínua (CI/CD) que a comunidade de software usa há décadas para aplicações tradicionais ao mundo dos modelos de IA. Este processo é às vezes chamado de CD4ML (Continuous Delivery for Machine Learning).
Em um pipeline de CI/CD para IA bem projetado, quando um cientista de dados propõe uma mudança no modelo um novo algoritmo, novos hiperparâmetros, uma nova feature essa mudança dispara automaticamente uma série de verificações: o modelo é treinado em um conjunto de dados de validação, seus resultados são comparados com o modelo em produção, testes de performance e fairness são executados, e só então, se tudo passar, o novo modelo é promovido para produção de forma gradual, através de uma estratégia de canary deployment que expõe o novo modelo a uma pequena fração do tráfego antes de fazer o rollout completo.
Conforme destacado por pesquisas de 2024 publicadas no Medium por especialistas em arquitetura de IA, ferramentas como BentoML introduziram em 2024 capacidades específicas para lidar com o deployment de Large Language Models (LLMs), que apresentam desafios únicos relacionados ao tempo de carregamento dos pesos do modelo e à gestão de memória GPU.
Monitoramento de modelos: Quando a IA envelhece
Um modelo de machine learning que funcionava perfeitamente na semana passada pode estar degradado hoje. Não porque o código mudou, mas porque o mundo mudou os dados com os quais o modelo foi treinado não refletem mais a realidade atual. Este fenômeno chama-se data drift ou concept drift, e é um dos maiores desafios operacionais de sistemas de IA em produção.
Em uma arquitetura de microsserviços para IA, o monitoramento de modelos é ele próprio um serviço ou um conjunto de serviços. Este serviço coleta continuamente as previsões do modelo, compara a distribuição dos inputs atuais com a distribuição dos dados de treinamento, monitora métricas de negócio associadas às previsões (conversões, cliques, reclamações) e dispara alertas ou automaticamente inicia um ciclo de retreinamento quando os limites são ultrapassados.
A arquitetura orientada a eventos é particularmente elegante para este caso de uso: o serviço de inferência publica eventos a cada previsão feita; o serviço de monitoramento é assinante desse stream de eventos, processa-os de forma assíncrona e mantém estatísticas rolantes sem adicionar latência ao caminho crítico de resposta.
Arquitetura orientada a eventos: O sistema nervoso da IA distribuída
Por que eventos são melhores que chamadas diretas
Imagine dois microsserviços que precisam se comunicar. A forma mais óbvia é a chamada direta: o Serviço A envia uma requisição HTTP ao Serviço B e aguarda a resposta. Simples, intuitivo e repleto de problemas quando o sistema cresce.
Se o Serviço B estiver lento, o Serviço A fica bloqueado esperando. Se o Serviço B cair, o Serviço A falha junto. E se amanhã surgir um Serviço C que também precisa saber o que o Serviço A está fazendo, é preciso modificar o código do Serviço A para enviar notificações ao Serviço C criando um acoplamento que, com o tempo, transforma a arquitetura de microsserviços em um emaranhado tão difícil de manter quanto o monólito que substituiu.
A arquitetura orientada a eventos (Event-Driven Architecture EDA) inverte esta lógica. Em vez de o Serviço A chamar diretamente o Serviço B, ele publica um evento “pedido realizado”, “modelo atualizado”, “anomalia detectada” em um broker de mensagens como Apache Kafka. Qualquer serviço interessado naquele tipo de evento se inscreve no broker e o processa de forma assíncrona, sem que o publicador saiba quem são os assinantes.
Conforme documentado em um artigo do World Journal of Advanced Research and Reviews de 2025, arquiteturas orientadas a eventos alcançam menor latência comparadas a modelos tradicionais de requisição-resposta, e plataformas de processamento de eventos baseadas em cloud conseguem lidar com volumes substanciais de eventos por segundo capacidade essencial para sistemas de IA que processam transações em escala global.
Event sourcing e CQRS: padrões para consistência em escala
Dois padrões arquiteturais tornaram-se indispensáveis para sistemas de IA distribuídos que precisam manter consistência de dados: Event Sourcing e CQRS (Command Query Responsibility Segregation).
O Event Sourcing propõe que o estado de um sistema não seja armazenado como um snapshot do estado atual, mas como uma sequência de eventos que levaram a esse estado. Imagine um sistema de recomendações: em vez de armazenar apenas “o usuário gosta de filmes de ficção científica”, o sistema armazena toda a sequência de eventos cada filme assistido, cada avaliação dada, cada busca realizada. Isso tem duas vantagens cruciais para IA: primeiro, permite reconstruir o histórico completo do comportamento do usuário para treinar modelos mais sofisticados; segundo, permite “viajar no tempo” para auditar o comportamento do sistema em qualquer ponto do passado.
Dados de pesquisa publicados no International Journal of Science and Technology mostram que a implementação de Event Sourcing junto com o padrão Saga utilizado para coordenar transações distribuídas entre múltiplos microsserviços alcança consistência de estado em 99,98% dos casos, com tempos de reconstrução de estado de cerca de 450 milissegundos para workflows envolvendo até 8 microsserviços.
O CQRS complementa o Event Sourcing ao separar as operações de leitura das de escrita em serviços distintos. Para sistemas de IA com alta razão leitura/escrita como um sistema de recomendações que faz centenas de consultas por segundo mas atualiza os modelos apenas periodicamente isto permite escalar as operações de leitura independentemente das de escrita. Estudos indicam que sistemas implementando o padrão CQRS alcançam 58% de redução na sobrecarga de comunicação entre serviços, e plataformas que adotam esta abordagem relatam 84% de redução em problemas de contenção de banco de dados.
A arquitetura de agentes de IA em microsserviços
O cenário mais avançado e mais promissor é a integração de agentes autônomos de IA dentro de uma arquitetura de microsserviços. Um agente de IA, neste contexto, é um microsserviço com capacidade de raciocínio: ele percebe o ambiente através de eventos, decide quais ações tomar com base em seu modelo de linguagem ou de decisão, e age através de chamadas a outros microsserviços.
Conforme analisado em um artigo da Pluralsight sobre arquitetura de IA agêntica, em uma arquitetura de LLM baseada em microsserviços, o agente recebe input do sistema mais amplo que serve como gatilho e melhora o contexto para raciocínio acessando serviços de memória de curto e longo prazo. Durante o raciocínio, o LLM pode continuar referenciando serviços de memória para refinar seu entendimento e decompor o objetivo em uma lista de tarefas. Através da comunicação orientada a eventos, uma mensagem colocada em uma fila pode acionar um agente de IA sem que o remetente precise saber quem ou quantos componentes estão escutando ou como vão responder.
Esta arquitetura tem consequências profundas para o futuro dos sistemas empresariais. Em vez de sistemas rígidos que executam fluxos pré-programados, passamos a ter ecossistemas adaptativos onde agentes de IA colaboram cada um especializado em um domínio específico para resolver problemas que nenhum agente isolado conseguiria resolver.
Os desafios reais: O que ninguém conta nas apresentações de conferência
A complexidade operacional como custo oculto
Toda escolha arquitetural tem um custo. O custo dos microsserviços é a complexidade operacional e é um custo que muitas organizações subestimam gravemente até que já estejam profundamente comprometidas com a abordagem.
Um monólito bem projetado tem um único ponto de deploy, um único processo para monitorar, um único banco de dados para administrar. Uma arquitetura de microsserviços com 50 serviços tem 50 pontos de deploy independentes, 50 processos para monitorar, possivelmente 50 bases de dados distintas, e uma malha de comunicação entre todos eles que pode falhar de formas que são difíceis até de imaginar, muito menos de testar.
Uma pesquisa sobre migração para arquiteturas de microsserviços orientadas a eventos, publicada em 2025, revelou que 73% das organizações enfrentam desafios significativos durante a migração, particularmente relacionados à comunicação entre serviços, consistência de dados e alinhamento organizacional. A mesma pesquisa documentou que sistemas monolíticos experimentam degradação de performance de 76% sob condições de alta carga, enquanto arquiteturas de microsserviços mantêm performance mais consistente, com degradação de apenas 24% mas atingir esta eficiência requer um nível de maturidade operacional que não se constrói da noite para o dia.
O problema da consistência de dados
Em um monólito com um único banco de dados, as transações ACID (Atomicity, Consistency, Isolation, Durability) garantem que ou todas as operações de uma transação são executadas com sucesso, ou nenhuma delas é. Esta garantia simplifica imensamente o desenvolvimento.
Em uma arquitetura de microsserviços, cada serviço tem seu próprio banco de dados, e transações que cruzam fronteiras de serviço não têm as mesmas garantias. Um pedido de compra que precisa reservar estoque, debitar o saldo do cliente e registrar a venda em três serviços diferentes pode terminar em estados inconsistentes se qualquer uma das três operações falhar.
Um estudo da Cloud Native Computing Foundation revelou que 67% das organizações consideram a consistência de dados um dos principais desafios em arquiteturas de microsserviços. O caso do LinkedIn é particularmente ilustrativo: a empresa implementou event sourcing em seu sistema de recomendação de conteúdo impulsionado por IA e relatou 50% de redução em inconsistências de dados e 30% de melhoria na confiabilidade do sistema.
A granularidade do serviço: O dilema de goldilocks
Um dos julgamentos mais difíceis em qualquer projeto de microsserviços é determinar o tamanho ideal de cada serviço. Serviços excessivamente pequenos às vezes chamados de nanoserviços introduzem latência de rede em operações que seriam instantâneas em um monólito, criam overhead operacional para cada novo serviço adicionado e tornam o sistema difícil de entender em sua totalidade. Serviços excessivamente grandes perdem os benefícios da independência e da escalabilidade granular.
Para sistemas de IA, este dilema tem dimensões adicionais. Um modelo de machine learning muito complexo pode justificar seu próprio serviço dedicado; um modelo simples pode ser incorporado em um serviço mais abrangente sem perda significativa de flexibilidade. A decisão deve ser guiada por padrões de escalonamento componentes que precisam de recursos muito diferentes dos demais são candidatos naturais à separação e por padrões de evolução componentes que mudam com frequências muito diferentes devem ser independentes para que a evolução de um não force o redeploy do outro.
Segurança em um mundo distribuído
Em um monólito, a fronteira de segurança é clara: tudo dentro do processo está implicitamente autorizado a se comunicar com tudo o mais. Em uma arquitetura de microsserviços, cada chamada entre serviços é uma chamada de rede e chamadas de rede podem ser interceptadas, falsificadas ou manipuladas.
O modelo de segurança Zero Trust “nunca confie, sempre verifique” tornou-se o padrão para sistemas de microsserviços modernos. Neste modelo, cada serviço deve autenticar e autorizar cada requisição recebida, independentemente de onde ela vem. Certificados mTLS (mutual TLS), implementados automaticamente pelo service mesh, garantem que apenas serviços autorizados possam se comunicar entre si, e que todo tráfego seja criptografado em trânsito incluindo tráfego interno ao cluster.
Para sistemas de IA, a segurança tem uma dimensão adicional: a proteção dos modelos em si. Um modelo de machine learning treinado em dados proprietários é um ativo valioso potencialmente mais valioso que os dados que o geraram. Arquiteturas bem projetadas incluem controles de acesso granulares para operações de leitura e escrita em model registries, e implementam estratégias de model encryption para proteger os pesos dos modelos em repouso e em trânsito.
O mercado, os números e o horizonte
O tamanho da transformação
As cifras que descrevem o crescimento do mercado de microsserviços revelam não apenas uma tendência tecnológica, mas uma transformação estrutural da indústria de software. O mercado global de arquitetura de microsserviços foi avaliado em 6,27 bilhões de dólares em 2024 e projeta-se que cresça a uma taxa anual composta de 21%, atingindo 15,97 bilhões de dólares até 2029. Não por acaso, esse crescimento é amplamente impulsionado pela adoção de sistemas de IA.
O mercado de gerenciamento de APIs a infraestrutura de comunicação que conecta os microsserviços segue trajetória ainda mais acentuada: avaliado em 5,42 bilhões de dólares em 2024, projeta-se que alcance 32,77 bilhões de dólares até 2032, com crescimento anual de 25%. Este dado reflete a centralidade das APIs como contratos de comunicação no ecossistema de microsserviços distribuídos.
As tendências que moldam 2025 e além
Três tendências convergentes estão redefinindo o estado da arte em arquiteturas de microsserviços para IA.
A primeira é a arquitetura MACH Microservices, API-first, Cloud-native, Headless. Esta abordagem vai além da decomposição técnica de serviços para propor um modelo filosófico de composição: cada capacidade de negócio é exposta como uma API first-class, os serviços são projetados para serem “headless” sem uma interface de usuário embutida e a infraestrutura é nativamente cloud. Para sistemas de IA, o MACH simplifica a integração de modelos de linguagem, serviços de visão computacional e outros componentes de IA em stacks heterogêneas de tecnologia.
A segunda é a fusão com o edge computing o processamento de dados próximo à fonte de geração, em vez de no datacenter central. Para sistemas de IA, isto é revolucionário: modelos de inferência podem rodar diretamente em dispositivos IoT, câmeras de segurança, veículos autônomos, reduzindo dramáticamente a latência e eliminando a necessidade de enviar dados sensíveis para a nuvem. A combinação de microsserviços com edge computing é especialmente potente para aplicações de IA em tempo real, como detecção de anomalias em linhas de produção industrial ou diagnóstico médico assistido por IA em regiões com conectividade limitada.
A terceira é o serverless computing dentro de frameworks de microsserviços. Plataformas como AWS Lambda, Google Cloud Functions e Azure Functions permitem que componentes de IA sejam executados sob demanda, sem gestão de infraestrutura subjacente, com cobrança por requisição. Para cargas de trabalho esporádicas um modelo que é consultado apenas ocasionalmente por uma equipe interna de analytics isso pode reduzir custos de forma dramática.
AIOps: Quando a IA gerencia a própria infraestrutura
A fronteira mais emocionante e talvez a mais especulativa é o AIOps: o uso de inteligência artificial para gerenciar e otimizar a própria infraestrutura de IA. Organizações usam IA para monitorar APIs, otimizar workflows de microsserviços e prever falhas do sistema antes que elas ocorram. Aplicações de IA em tecnologia de integração incluem manutenção preditiva com resolução automatizada de problemas onde o sistema detecta um padrão de comportamento anômalo e toma ação corretiva antes mesmo que o incidente cause impacto ao usuário.
Um artigo publicado na revista Electronics em 2025, intitulado “A Practical Approach to Defining a Framework for Developing an Agentic AIOps System”, documenta como agentes de IA podem ser projetados especificamente para interagir com e otimizar sistemas de microsserviços fechando o loop entre IA como conteúdo da arquitetura e IA como gestora da arquitetura.
Estudos de caso: Quando a teoria encontra a produção
Netflix: O laboratório de microsserviços do mundo
A Netflix é frequentemente citada como o exemplo mais emblemático de uma migração bem-sucedida de uma arquitetura monolítica para microsserviços e por boas razões. A empresa iniciou sua jornada por volta de 2009, após uma falha catastrófica que deixou o serviço de DVD inoperante por três dias, e completou a migração para microsserviços em 2016. Hoje opera com centenas de serviços independentes, incluindo um sofisticado ecossistema de IA para recomendações, personalização de thumbnails, otimização de qualidade de streaming adaptativo e previsão de demanda por conteúdo.
O sistema de recomendações da Netflix é um caso de estudo em si: combina dezenas de modelos especializados um para previsão de engajamento de curto prazo, outro para previsão de retenção de longo prazo, outro para personalização de artwork cada um servido por um microsserviço dedicado, com seus próprios ciclos de treinamento e seus próprios SLAs de latência. O resultado é uma plataforma que consegue escalar a inteligência das recomendações de forma independente da infraestrutura de streaming.
Amazon: A IA na cadeia de suprimentos
Um caso documentado publicamente pela AWS em 2024 descreve como a Amazon implementou uma simulação baseada em agentes de IA para sua cadeia de abastecimento de entrada, utilizando precisamente a arquitetura de microsserviços orientada a eventos descrita neste artigo. Centenas de agentes de IA cada um simulando um fornecedor, um centro de distribuição ou um padrão de demanda operaram concorrentemente, publicando e consumindo eventos através de uma infraestrutura de mensageria, para otimizar decisões logísticas que seriam computacionalmente intratáveis com abordagens convencionais.
Capital one: A transformação bancária
No setor financeiro, a Capital One é frequentemente citada como referência em adoção de microsserviços para sistemas regulados. A transformação da empresa envolveu a identificação de mais de 300 eventos de negócio distintos no domínio de banking de consumo desde aprovações de crédito até detecção de fraudes cada um modelado como um evento de primeira classe na arquitetura orientada a eventos. Modelos de machine learning para detecção de fraude e scoring de crédito foram encapsulados em microsserviços dedicados, permitindo atualizações frequentes dos modelos sem impacto nos sistemas de core banking.
Epílogo: A arquitetura como filosofia
Há uma frase atribuída ao arquiteto de software Mel Conway, cunhada em 1967 e conhecida como Lei de Conway, que continua sendo mais verdadeira do que a maioria das pessoas gostaria de admitir: “Qualquer organização que projeta um sistema produzirá um design cuja estrutura é uma cópia da estrutura de comunicação da organização.”
A arquitetura de microsserviços para sistemas de IA é, em última análise, tanto uma escolha organizacional quanto uma escolha técnica. Ela funciona melhor quando as equipes que desenvolvem os serviços são tão independentes quanto os serviços que desenvolvem o famoso modelo de “equipes de duas pizzas” da Amazon, onde uma equipe deve ser pequena o suficiente para ser alimentada por duas pizzas. Ela prospera em culturas que valorizam a autonomia, a responsabilidade e a experimentação rápida.
E ela falha ou produz resultados muito aquém do potencial quando é adotada como uma moda tecnológica, sem o investimento correspondente em observabilidade, automação, cultura de engenharia e maturidade organizacional.
O estado da arte, em 2026, aponta para um futuro onde a fronteira entre o sistema de IA e a infraestrutura que o suporta se torna cada vez mais tênue. Agentes de IA gerenciam outros agentes de IA. Pipelines de MLOps se auto-otimizam com base nos padrões que observam. O service mesh aprende, com aprendizado de máquina, quais políticas de roteamento maximizam a performance do sistema como um todo.
Este futuro não é ficção científica. É o estado da arte emergente, documentado em dezenas de papers acadêmicos publicados nos últimos 24 meses, validado em produção por empresas de todos os tamanhos ao redor do mundo.
A revolução é silenciosa porque acontece nas camadas de infraestrutura, invisíveis ao usuário final. Mas suas consequências são profundas: estamos construindo, pela primeira vez na história, sistemas de software que são não apenas escaláveis e resilientes, mas genuinamente adaptativos capazes de aprender, de se otimizar, de responder ao mundo com uma agilidade que nenhuma arquitetura anterior tornava possível.
O monólito era uma catedral. Os microsserviços são uma cidade. E a inteligência artificial é o que faz essa cidade aprender a se governar.
Fontes
- Designing Microservices Using AI: A Systematic Literature Review — MDPI, março de 2025. Revisão sistemática de 43 estudos publicados entre 2018 e 2024 sobre a aplicação de IA no design de microsserviços.
https://www.mdpi.com/2674-113X/4/1/6 - AI Techniques in the Microservices Life-Cycle: a Systematic Mapping Study — Computing, Springer Nature, março de 2025. Mapeamento sistemático de 269 papers sobre uso de IA em microsserviços.
https://link.springer.com/article/10.1007/s00607-025-01432-z - Willard, J. & Hutson, J. — The Evolution and Future of Microservices Architecture with AI-Driven Enhancements — International Journal of Recent Engineering Science (IJRES), vol. 12, n. 1, pp. 16-22, 2025.
https://ijresonline.com/archives/ijres-v12i1p103 - Vudayagiri, V. — Scalable AI-Driven Microservices Architectures for Distributed Cloud Environments — International Journal of Computer Engineering and Technology, 15(6), 154–168, 2024.
https://iaeme.com/MasterAdmin/Journal_uploads/IJCET/VOLUME_15_ISSUE_6/IJCET_15_06_013.pdf - Scalable MLOps Pipeline with Complexity-Driven Model Selection Using Microservices — MDPI Technologies, vol. 14, n. 1, 2026. Estudo sobre pipeline de MLOps auto-otimizante baseado em microsserviços com Kubernetes e Kubeflow.
https://www.mdpi.com/2227-7080/14/1/45 - Building AI-Driven Cloud-Native Applications — MLOps Architecture on Kubernetes — International Journal of Science and Computer Applications (IJSCIA), vol. 6, n. 2, 2025. Validação empírica de arquitetura cloud-native com latência de inferência abaixo de 120ms.
https://www.ijscia.com/wp-content/uploads/2025/04/Volume6-Issue2-Mar-Apr-No.862-328-340.pdf - Cloud Microservices in Focus: Architecture, Industry Practices and Emerging Innovation — International Research Journal on Advanced Engineering Hub (IRJAEH), vol. 3, n. 12, 2025. Análise de padrões de circuit breaker, orquestração e zero-trust em microsserviços.
https://irjaeh.com/index.php/journal/article/view/1168 - Distributed Systems in Modern Enterprise Architecture — International Journal of Science and Technology (IJSAT), 2025. Análise de CQRS, Event Sourcing e padrões de tolerância a falhas em microsserviços.
https://www.ijsat.org/papers/2025/1/2447.pdf - Event-Driven Architectures for Microservices: A Framework — International Journal of Science and Technology (IJSAT), 2025. Framework para migração de arquiteturas monolíticas para microsserviços orientados a eventos.
https://www.ijsat.org/papers/2025/1/2498.pdf - Microservices and Event-Driven Architecture: Revolutionizing E-Commerce — World Journal of Advanced Research and Reviews, 26(02), 734-742, 2025.
https://journalwjarr.com/sites/default/files/fulltext_pdf/WJARR-2025-1663.pdf - Architecting Microservices for Seamless Agentic AI Integration — Pluralsight, 2025. Análise de como agentes de IA baseados em LLMs integram-se a arquiteturas de microsserviços orientadas a eventos.
https://www.pluralsight.com/resources/blog/ai-and-data/architecting-microservices-agentic-ai - MLOps in the Cloud-Native Era — Scaling AI/ML Workloads with Kubernetes and Serverless Architectures — Cloud Native Now, abril de 2025.
https://cloudnativenow.com/topics/cloudnativedevelopment/kubernetes/mlops-in-the-cloud-native-era-scaling-ai-ml-workloads-with-kubernetes-and-serverless-architectures/ - Microservices Architecture for AI Applications: Scalable Patterns and 2025 Trends — Medium / Meeran Malik, maio de 2025. Panorama das ferramentas KServe, BentoML, Argo e tendências de deployment de LLMs.
https://medium.com/@meeran03/microservices-architecture-for-ai-applications-scalable-patterns-and-2025-trends-5ac273eac232 - MLOps Concepts — Azure Kubernetes Service — Microsoft Learn, documentação oficial. Definição e componentes essenciais do MLOps aplicado ao ciclo de vida de modelos de ML.
https://learn.microsoft.com/en-us/azure/aks/concepts-machine-learning-ops - Integration Trends 2026: API, Microservices & EDA — Novasarc, janeiro de 2026. Dados de mercado sobre crescimento do segmento de microsserviços e gerenciamento de APIs.
https://www.novasarc.com/integration-trends-2026-api-microservices-eda - The Ultimate Guide to Integrating AI Agents into Microservice Ecosystems — Klover.ai, 2025. Análise da sinergia entre agentes de IA e microsserviços em implantações empresariais reais.
https://www.klover.ai/the-ultimate-guide-to-integrating-ai-agents-into-microservice-ecosystems/ - Kubernetes Service Mesh: Ultimate Guide — Plural.sh, fevereiro de 2025. Análise detalhada de service meshes (Istio, Linkerd) para gestão de comunicação em microsserviços.
https://www.plural.sh/blog/kubernetes-service-mesh-guide/ - Amrit, C. & Narayanappa, A. K. — An Analysis of the Challenges in the Adoption of MLOps — Journal of Innovation & Knowledge, 8, 100653, 2024.
https://doi.org/10.1016/j.jik.2024.100653