O mito do algoritmo perfeito
Houve um tempo, no alvorecer da era do Big Data, em que acreditávamos que o segredo da inteligência artificial residia exclusivamente na sofisticação dos modelos. Imaginávamos que, se tivéssemos redes neurais suficientemente complexas, elas poderiam digerir qualquer coisa e expelir sabedoria. Estávamos equivocados. O que os últimos anos nos ensinaram e o que 2026 consolidou como dogma é que a IA não é uma criatura de lógica pura, mas um organismo biológico digital: ela é o que ela come.
Se o modelo de Machine Learning é o motor de combustão, o pipeline ETL (Extração, Transformação e Carga) é a refinaria transcontinental que transforma o petróleo bruto e lodoso da internet em combustível de alta octanagem. Sem um pipeline ETL robusto, profundo e resiliente, o modelo mais caro do mundo não passa de uma máquina de gerar alucinações estatísticas. Este artigo disseca a anatomia dessa refinaria, revelando como o dado bruto é capturado, purificado e finalmente entregue ao altar da computação.
A tríade vital extração, transformação e carga
A extração: A grande pescaria no oceano de ruído
A jornada começa com a Extração. No contexto do Machine Learning, extrair não é meramente copiar arquivos. É um ato de curadoria em escala planetária. Os dados hoje são fragmentos dispersos em ecossistemas heterogêneos: logs de servidores em tempo real, bancos de dados relacionais legados, streams de redes sociais e sensores de IoT que nunca silenciam.
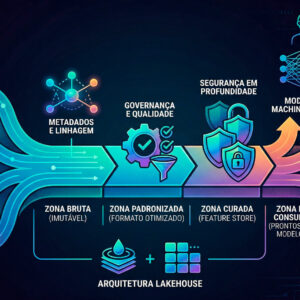
A extração moderna para ML exige o que a literatura acadêmica recente chama de “consciência de linhagem”. Não basta capturar o dado; o pipeline deve registrar de onde ele veio, em que condições foi gerado e qual era o contexto temporal. Em 2026, a extração deixou de ser um processo em lote (batch) para se tornar um fluxo contínuo, onde o sistema deve decidir, no milissegundo da captura, se aquela informação possui valor preditivo ou se é apenas ruído térmico.
A transformação: A alquimia da engenharia de atributos
Se a extração é a coleta, a Transformação é onde a ciência encontra a arte. Para o Machine Learning, transformar dados não significa apenas mudar o formato de uma data ou corrigir nomes próprios. É aqui que ocorre a Engenharia de Atributos (Feature Engineering) o processo de traduzir a realidade bruta em conceitos que a matemática consegue abraçar.
Imagine um sistema de crédito. O dado bruto diz que você comprou café às 08:00. A transformação converte isso em um “vetor de comportamento”: sua frequência de consumo, sua estabilidade de rotina e sua propensão ao risco, tudo normalizado em escalas numéricas precisas. Pesquisas publicadas em 2025 na IEICE Transactions destacam que a qualidade desta etapa é responsável por até 80% da performance final de um modelo. É a fase mais onerosa, exigindo limpeza de valores ausentes, tratamento de anomalias (outliers) e a complexa normalização que impede que uma variável de escala grande (como o salário) “sufoque” uma variável de escala pequena mas vital (como a idade).
A carga: O destino nos reservatórios de inteligência
Finalmente, a Carga. No ETL tradicional para business intelligence, o destino era um Data Warehouse estático. No Machine Learning, o destino evoluiu. Agora, carregamos dados em Feature Stores (Lojas de Atributos) e Vector Databases (Bancos de Dados Vetoriais). Estes repositórios não apenas armazenam o dado; eles o mantêm pronto para o consumo imediato por modelos em produção, garantindo que o que o modelo aprendeu no laboratório seja exatamente o que ele verá no mundo real.
Do ETL tradicional ao MLOps contínuo
A morte da estática e o nascimento do fluxo
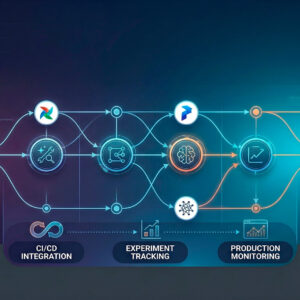
A grande diferença entre um pipeline de dados comum e um voltado para IA é o conceito de treinamento contínuo. Um modelo de IA começa a morrer no momento em que termina seu treinamento, pois o mundo muda (o fenômeno conhecido como Data Drift). O pipeline ETL moderno é, portanto, circular. Ele monitora a performance do modelo e, ao detectar que a realidade divergiu da teoria, dispara automaticamente um novo ciclo de extração e transformação.
Este ciclo é o coração do MLOps. Conforme documentado pela Microsoft em 2025, a integração entre o pipeline de dados e o ciclo de vida do modelo permite que empresas como Uber e Netflix atualizem suas inteligências milhares de vezes por dia sem intervenção humana manual.
Feature stores: A memória centralizada
Um dos maiores gargalos resolvidos recentemente foi o “desvio de treinamento-serviço”. Frequentemente, cientistas de dados transformavam os dados de um jeito para treinar o modelo, mas os engenheiros de software, meses depois, os transformavam de outro jeito para o sistema rodar. O resultado era o caos. A introdução das Feature Stores no pipeline ETL resolveu isso: o dado é transformado uma única vez e servido como uma “fonte da verdade” para ambos os mundos.
Desafios e o horizonte da IA centrada em dados
O custo da pureza: Viés e ética no pipeline
O pipeline ETL é também o local onde o preconceito humano é codificado em silício. Se a extração captura dados de uma sociedade desigual, a transformação pode amplificar essas desigualdades. Estudos da MDPI em 2025 mostram que o design do pipeline deve agora incluir etapas de “desenviesamento” (debiasing) automático, onde algoritmos revisam a transformação para garantir que características protegidas como etnia ou gênero não sejam usadas como substitutos (proxies) ocultos para decisões discriminatórias.
A revolução da IA centrada em dados (data-centric AI)
Estamos migrando da “IA Centrada em Modelos” para a “IA Centrada em Dados”. O foco não é mais ajustar o algoritmo até que ele funcione com dados ruins, mas usar o pipeline ETL para garantir que os dados sejam tão perfeitos que até algoritmos simples brilhem. Esta mudança filosófica coloca o engenheiro de dados o mestre do ETL no centro do palco tecnológico.
O fluxo infinito
O pipeline ETL para Machine Learning não é apenas uma sequência de passos técnicos; é o sistema nervoso da inteligência artificial. Ele é o que separa um brinquedo acadêmico de uma ferramenta que pode diagnosticar doenças, prever crises econômicas ou dirigir veículos autonomamente. No fim, a inteligência não reside apenas no “cérebro” do modelo, mas no fluxo constante e purificador de dados que o mantém vivo.
Fontes
- Designing Microservices Using AI: A Systematic Literature Review — MDPI, março de 2025. Analisa como o design de pipelines e serviços é otimizado por técnicas de IA.
https://www.mdpi.com/2674-113X/4/1/6 - Data Preprocessing and Feature Engineering for Machine Learning — IEICE Transactions, 2025. Um estudo exaustivo sobre o impacto das transformações de dados na precisão dos modelos.
Acesse a fonte - Vudayagiri, V. — Scalable AI-Driven Microservices Architectures — International Journal of Computer Engineering and Technology, 2024. Discute a escalabilidade de componentes de dados em nuvem.
Acesse a fonte - Scalable MLOps Pipeline with Complexity-Driven Model Selection — MDPI Technologies, 2026. Foca na automação do pipeline ETL integrado ao ciclo de vida de ML.
https://www.mdpi.com/2227-7080/14/1/45 - MLOps Concepts — Azure Kubernetes Service — Microsoft Learn, 2025. Documentação técnica sobre a operação de pipelines de ML em escala.
Acesse a fonte - Microservices Architecture for AI Applications: 2025 Trends — Medium / Meeran Malik, 2025. Panorama sobre ferramentas de serving e carga como BentoML e KServe.
Acesse a fonte